






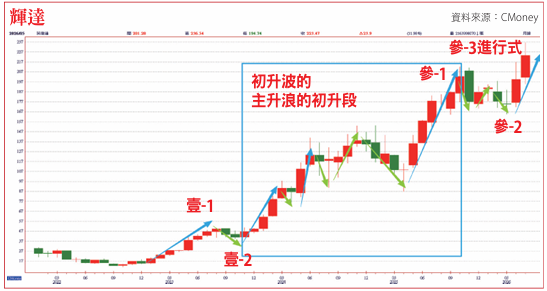
在傳統的稠密模型(Dense Model)中,所有Token都會經過模型的所有參數。但在MoE(Mixtureof Experts)架構中,模型被拆分成多個獨立的「專家(Experts)」。每當輸入一個Token,路由演算法就會動態決定把這個Token送給哪個一到兩個專家來運算。這些專家並非都在同一個晶片上,而是分散在數百甚至數千顆晶片中。
MoE核心戰場從單純算力 轉移到Scale-up高速互聯
這意味著在每一層的計算中,晶片之間都必須進行極其頻繁、高頻寬且超低延遲的Token交換(也就是全對全通訊)。如果通訊網絡不夠快,晶片算得再快,也會卡在等別的晶片把Token傳過來的瓶頸上。因此,MoE的核心戰場已經從單純的算力(Flops),轉移到了Pod內部的Scale-up高速互聯網路。
輝達很早就意識到單一晶片算力是有極限的,因此大力投資專屬的NVLink技術與NVSwitch晶片。輝達的解決方案是建立一個龐大的共享記憶體池,以NVL72或NVL576為例,它是透過獨立的交換器機架(Switch Tray),讓數百顆GPU在Pod內部實現任意兩點之間無阻塞、全頻寬、超低延遲的直接溝通。這就是標準的交換式擴充網路(Switched Scaleup)。
晶片間通訊延遲壓到十微秒以內
為什麼前沿AI實驗室Anthropic敢在亞馬遜的基礎設施上鎖定高達1000億美元的長期算力投入,因為Trainium 3的Switched架構,真的具備了吞下新一代MoE推理與訓練的胃口。
亞馬遜的Trainium在最新的硬體演進中,毅然決然放棄了舊架構,轉向與輝達相同的Switched技術路線。
亞馬遜在Trainium 3 UltraServer機櫃中進行了毀滅性的升級,推出了自研的NeuronSwitch-v1,並在單一機架中塞入了數百顆高頻寬交換晶片(如與Astera Labs合作的PCIe 6.0/Scale-up交換器)。這讓Trainium 3成功從「直連架構」轉型為「獨立交換托盤架構」,在單一系統內(Up to 144顆晶片)建立了高達20.7 TB HBM3e的超大共享記憶體池,並將晶片間通訊延遲壓到十微秒以內。
封裝、信號完整性與交換器硬體 Trainium 3展現超強恐怖整合力
亞馬遜透過Trainium 3展現了在封裝、信號完整性與交換器硬體上的恐怖整合力,成為除輝達外唯二能提供商用交換式擴充網路的巨頭,這正是為什麼Atreides Management投資長Gavin Bake認為它具備了與Nvidia NVLink叫板的Switched Scaleup能力。
預期亞馬遜的Trainium 3在下半年順利量產,並且Switched Scale-up Network(NeuronSwitch架構)真的能展現出媲美Nvidia Blackwell家族(NVL72)的MoE模型處理能力,這表示市場目前嚴重低估了亞馬遜作為AI算力垂直整合巨頭(ASIC霸主)的潛力,也意味著輝達在算力的霸主地位將被挑戰。
輝達是賣硬體的,客戶要承擔高昂的硬體資本支出,輝達現在的絕對壟斷(毛利率高達75%~80%),建立在兩個客戶不得不買的痛點上:(1)只有輝達能提供無阻塞、全頻寬的NVLink+NVSwitch交換式架構(Scale-up)。(2)CUDA的壟斷地位。
算力成本估比輝達便宜30%-50%
但是亞馬遜不需要單獨賣Trainium 3晶片給微軟或Meta。它只要把Trainium 3部署在自己的雲端,改以AWS雲端算力服務的形式租給客戶(例如Anthropic的Claude模型)。AWS自研晶片不需要像輝達一樣賺取高達75%的硬體毛利,預估Trainium 3提供的算力成本,可能會比同等級的輝達解決方案便宜30%到50%。
在當前AI巨頭瘋狂燒錢、急需降低ROI(投資回報率)的背景下,這種成本優勢具有改變算力格局的吸引力。過去大家不用非輝達晶片,另一個原因是因為軟體(如PyTorch)在非CUDA架構上跑不順。但亞馬遜擁有全美最頂尖的AI實驗室Anthropic作為鐵桿盟友,Anthropic的Neuron SDK優化已經到了爐火純青的地步。
當Claude 4或更高級的MoE模型在Trainium 3上跑出完美的吞吐量與超低延遲時,這就是最強廣告,其他SaaS廠商與企業級客戶會意識到:「原來不用CUDA,在AWS上用Neuron跑AI也完全沒問題。」
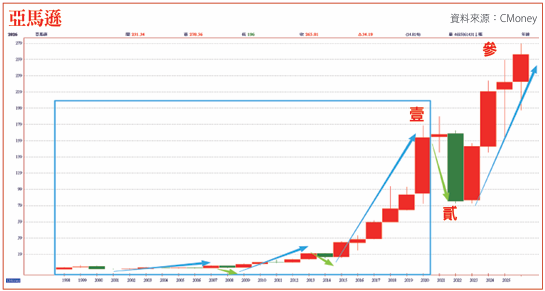
若Trainium 3量產並證明成功…
亞馬遜目前的股價反映的是最強的雲端與電商公司,但如果Trainium 3成功,它將被重新定價為全美唯一擁有自主Switched網絡生態的AI算力新霸主,這個議題很有可能是影響下半年投資績效排名的關鍵變數之一。
目前華爾街給予亞馬遜的估值,主要還是建立在兩個基礎上:電商業務的穩定現金流,以及AWS作為傳統雲端(IaaS/PaaS)龍頭的市佔率。目前AWS提供AI算力,很大一部分是跟輝達買GPU,這意味著大筆的錢被輝達賺走了。當AWS把自家機房的輝達GPU逐步替換成自研的Trainium 3,AWS不需要再支付輝達高額的硬體溢價。
可與輝達抗衡的AI算力新霸主
若Trainium 3成功替代AWS內部30%的AI算力需求,AWS的營業利益率預期能拉高3%-5%,這將直接為亞馬遜每年多創造數十億甚至上百億美元的純利。
目前微軟因為手握OpenAI,在AI雲端溢價上享有了更高的本益比,而亞馬遜的本益比往往被電商業務拉低,如果下半年Trainium 3量產並被證明成功,市場會開始將亞馬遜視為唯一能與輝達分庭抗禮的AI基礎設施巨頭。
只要華爾街將AWS業務的估值乘數(EV/Sales或P/E)往AI硬體與高階算力公司的方向修復15%-20%,反映在亞馬遜整體的市值上,就意味著至少3,000億到4,500億美元的市值成長空間,折合每股約有15%-25%的潛在低估空間。
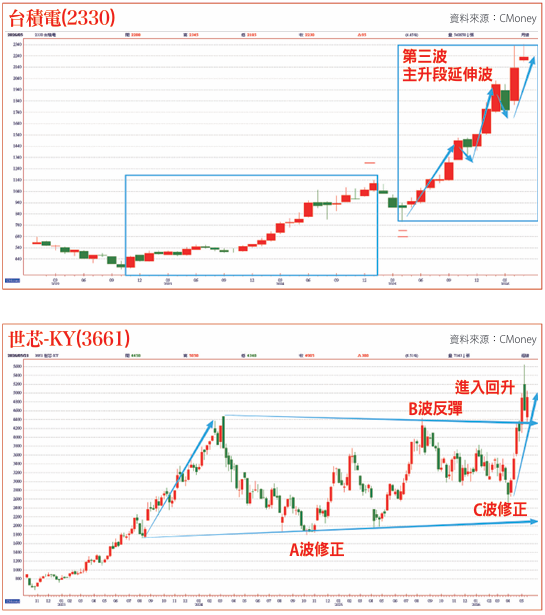
低估價值下半年兌現? 盯緊三個訊號
這個低估價值何時會兌現?下半年需要盯緊以下幾個訊號:
(1)留意Anthropic下半年推出的最新主力模型,是否高調宣稱完全基於AWS Trainium 3叢集訓練並提供推理支援。
(2)Trainium 3據傳採用了台積電的先進製程與高階封裝,亞馬遜向台積電包下的產能是否如期放大,是大量生產的硬指標。事實上,台積電第一季法說會提到將為三奈米新增一座廠房。
(3)世芯-KY作為亞馬遜ASIC的重要設計服務合作夥伴,它的月營收與拉貨動能,將是Trainium 3是否引爆的領先指引,而世芯在法說會上已經表示今年的營收將會創歷史新高,而且有八成營收集中在下半年。
更多文章就在 [理財周刊1344期] 👈點紅字看完整精彩內容